Built a Local-First RAG Research Tool with Nemotron + vLLM + Tool Calling
Introduction
Built a local-first RAG research tool that runs entirely on a single GPU. Sharing the approach since the tool calling + RAG combo took some figuring out.
Stack
In my case, Nemotron Nano 9B v2 Japanese on vLLM (FP16, RTX 5090), FastAPI + SQLite FTS5 + Jinja2 — entire backend is one app.py, NVIDIA's official parser plugins for tool calling and reasoning
Key Design Decisions
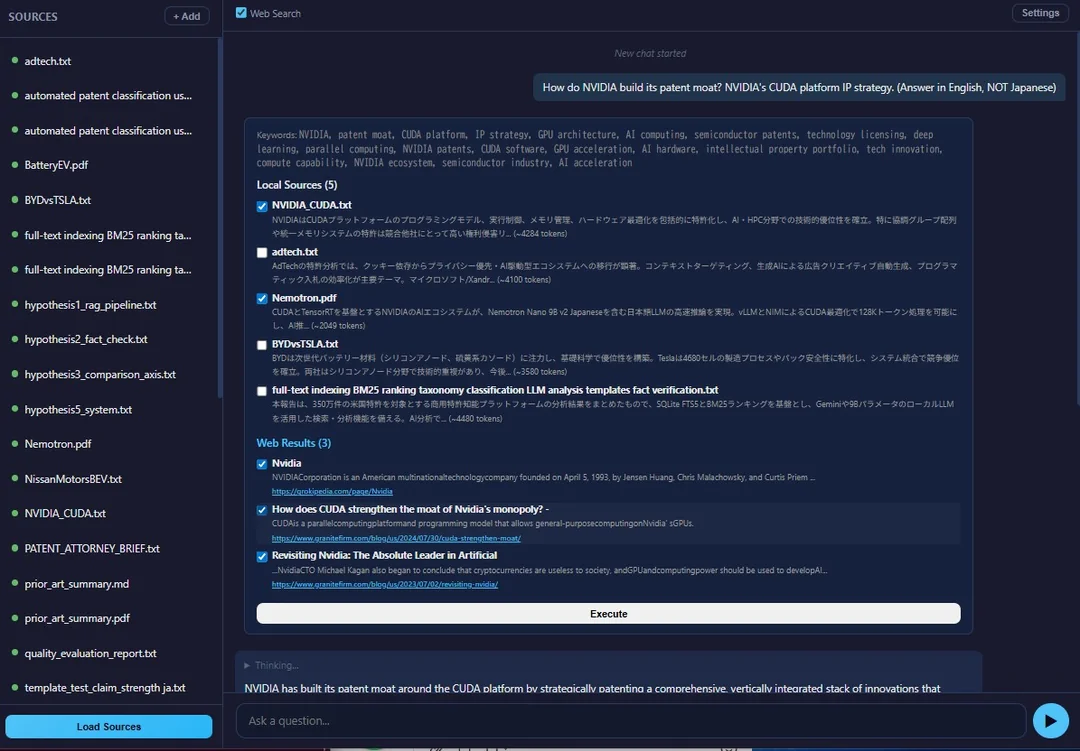
Extract → Execute Two-Step Flow
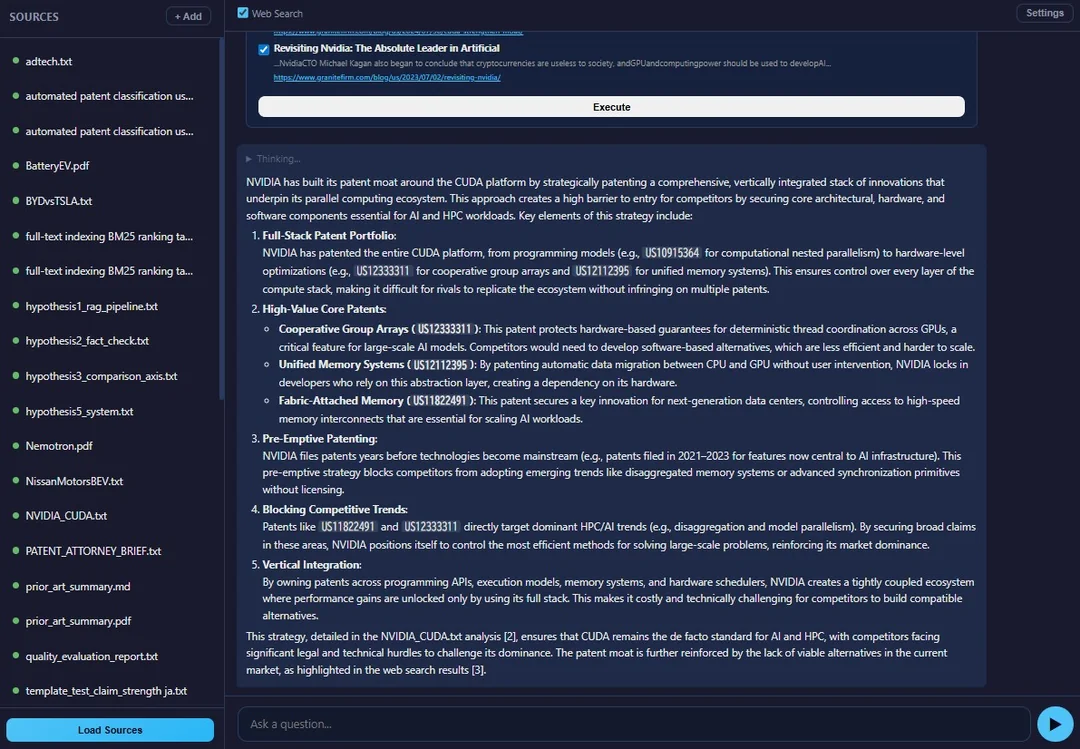
When you ask a question, the system first extracts bilingual keywords (EN+JA) via LLM, runs FTS5 search on local sources AND DuckDuckGo web search in parallel, then shows you what it found — with checkboxes. You pick what's relevant, hit Execute, and only then does it generate. This avoids dumping 100k+ tokens of context and hoping the model figures it out.
Tool Calling
Nemotron v2 supports tool calling but needs custom parser plugins (not the built-in vLLM parsers — those are for v3). With and , the model autonomously decides when to search the web. Works surprisingly well at temp 0.1.
Prefix Cache Warmup
Instead of caching everything at source load, the KV cache is warmed up when the user sees the source preview (step 3). By the time they click Execute, the prefix is already cached. on vLLM.
Bilingual FTS5 Search
User query → Nemotron extracts keywords in both English and Japanese → OR-joined FTS5 MATCH query. Simple but effective for multilingual patent/research data.
Numbers
- ~80-120 tok/s output
- 8192 max tokens
- Source extraction: ~3-5s (keyword extraction + FTS5 + DDG parallel)
- Full response with 5 sources + 3 web results: ~50s for a detailed answer
- *RTX 5090
Source Code
GitHub: https://github.com/soy-tuber/SoyLM
One file app, and go. Needs vLLM with the Nemotron parser plugins separately.
Original Post
Reddit r/LocalLLaMA: https://www.reddit.com/r/LocalLLaMA/comments/1s0lsi8/